Cerebras WSE-3 : 4 billions de transistors et 900 000 cœurs IA |
————— 14 Mars 2024 à 16h38 —— 26736 vues



Cerebras WSE-3 : 4 billions de transistors et 900 000 cœurs IA |
————— 14 Mars 2024 à 16h38 —— 26736 vues
Cerebras Systems Inc. une entreprise américaine fondée en 2015 qui est spécialisée dans le domaine de l'intelligence artificielle, vient de présenter la troisième génération de son Wafer Scale Engine : le WSE-3. Fidèle à sa lignée, cette version fait toujours dans la démesure : fabriquée par TSMC à partir de processus 5 nm, la puce compte 4 billions de transistors, 900 000 cœurs optimisés pour l’IA, 44 Go de SRAM, pour une performance de pointe de 125 petaflops FP16. Cerebras affirme que cette génération délivre des performances deux fois supérieures à celles de la précédente version, le WSE-2, pour une consommation et un tarif similaires.

Wafer Scale Engine-3 © Cerebras
Ce WSE-3 sert à équiper les systèmes Cerebras CS-3. Ces derniers prennent en charge 1,5 To, 12 To ou carrément 1,2 Po de mémoire externe. Cette quantité de mémoire permet de stocker des modèles massifs dans un espace logique unique sans partitionnement ni remaniement selon l’entreprise. Ainsi, il sont en mesure d’entraîner des modèles IA à 24 billions de paramètres. Pour contextualiser, GPT-4 implique 1,76 billion de paramètres.
Pour le WSE-2, Cerebras avait mis en scène le gigantisme de la puce à travers quelques illustrations éloquentes pour le grand public.

Wafer Scale Engine-2 © Cerebras
Pas de rapprochements de ce genre pour le WSE-3, mais l’habituel comparaison avec le plus gros des GPU actuels. En l’occurrence, le H100 de NVIDIA, qui est déjà un sacré engin avec ses 80 milliards de transistors et sa surface de 814 mm².
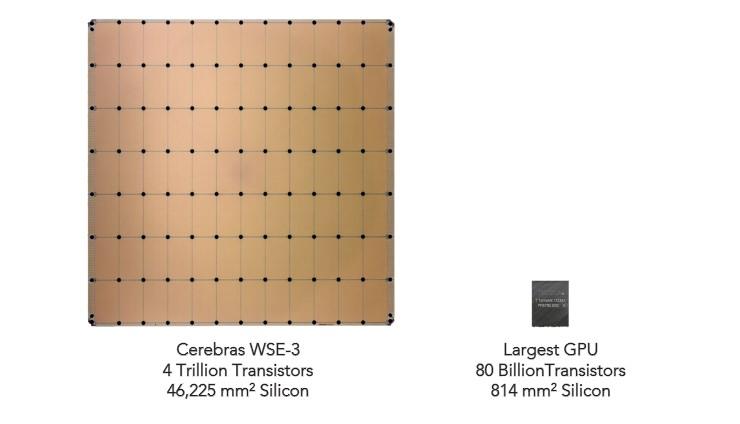
Wafer Scale Engine-3 vs H100 © Cerebras
La société se livre à cette comparaison depuis la toute première version du WSE. Si la surface n'évolue pas au fil des ans, le nombre de transistors est logiquement en hausse perpétuelle à mesure que la finesse de gravure s'affine : 16 nm, 7 nm, puis 5 nm désormais.


Les spécifications des deux premières générations de WSE © Cerebras
Pour en revenir à la H100, Cerbras poursuit la comparaison avec la puce de NVIDIA dans les tableaux comparatifs ci-dessous. Naturellement, c’est un peu David contre Goliath ; comme comparer des choux et des carottes.
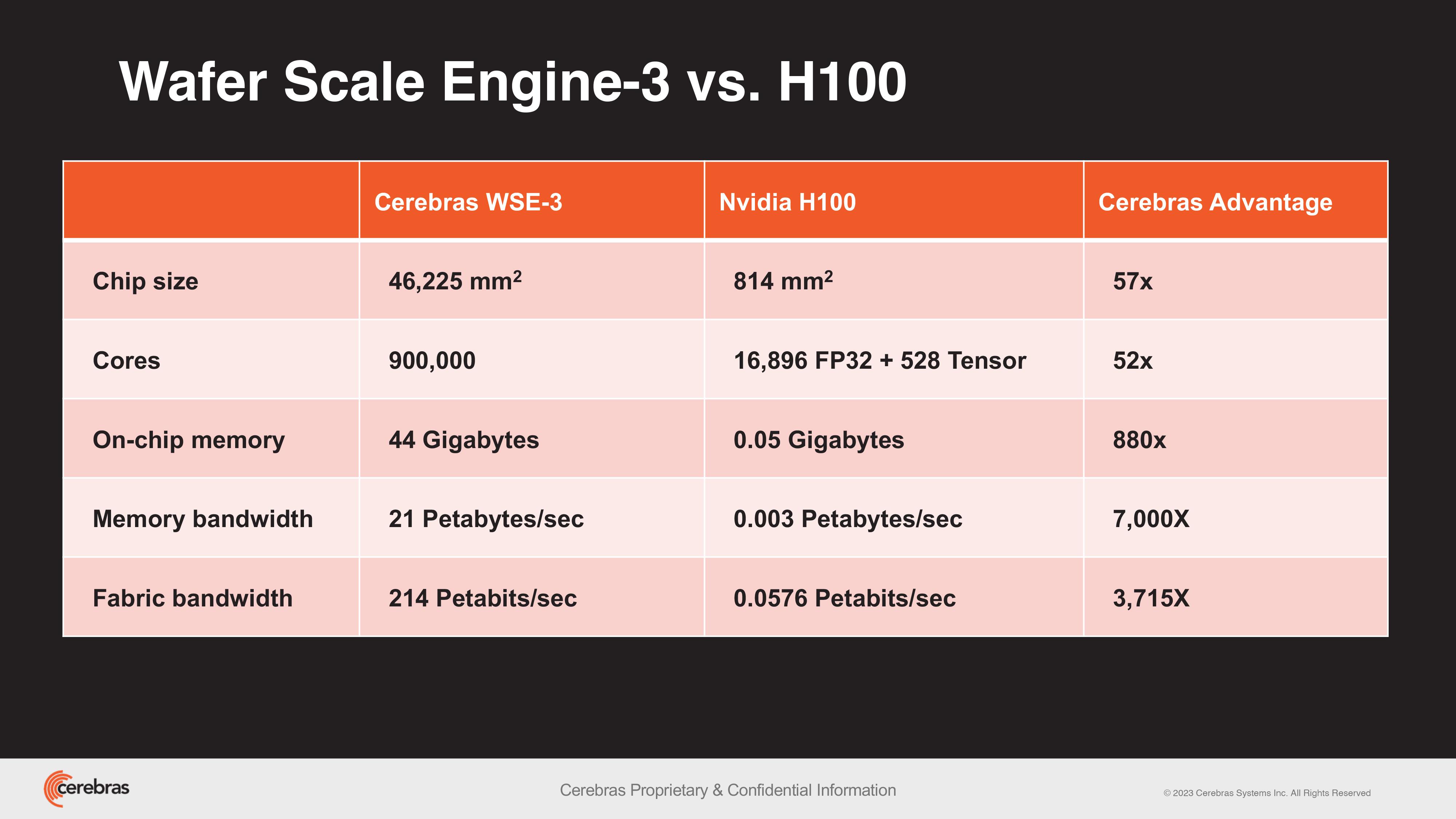
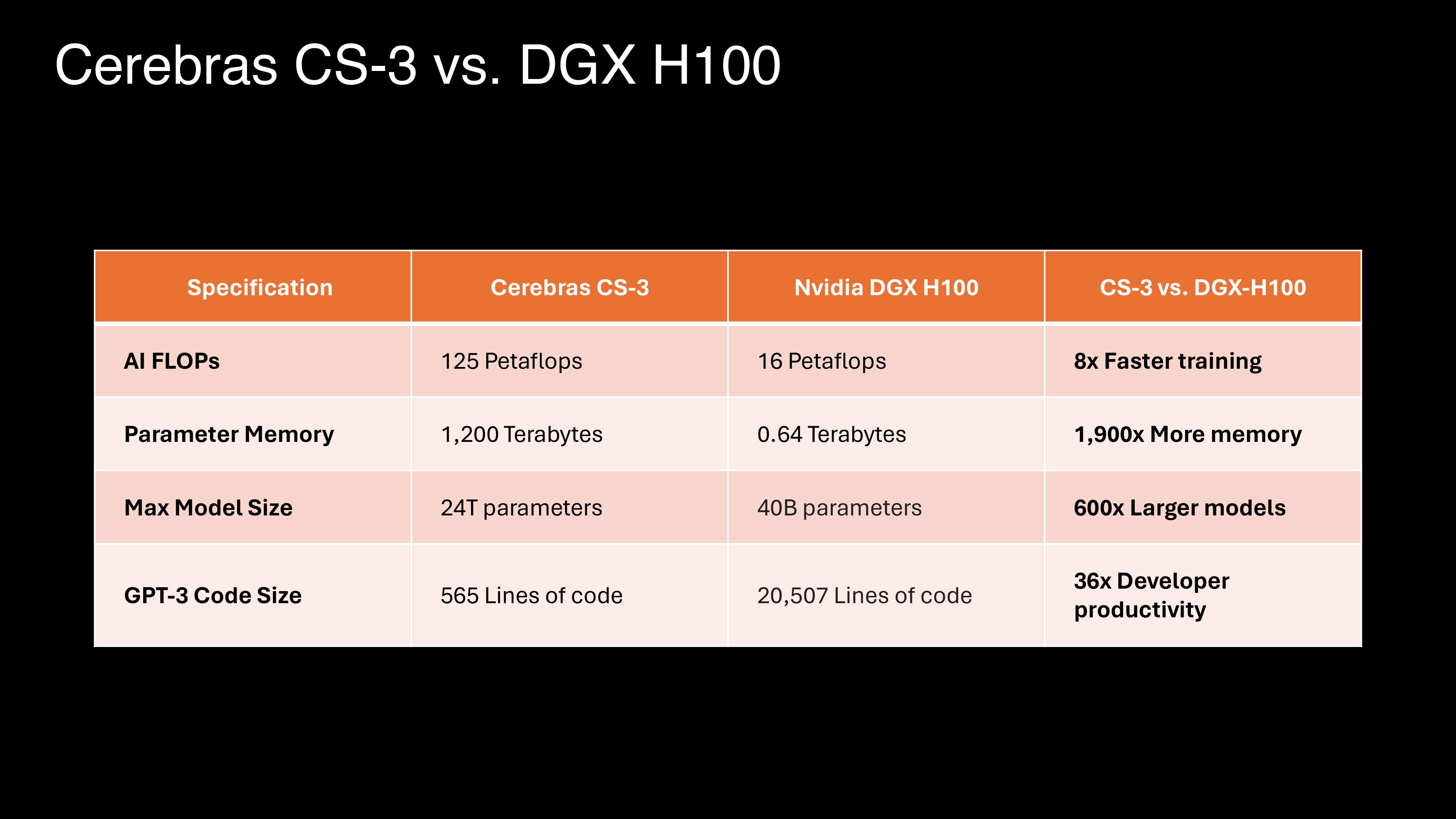
Comme l’explique l’entreprise dans son communiqué de presse, l’énorme système de mémoire du CS-3 est conçu pour former des grands modèles de langage (LLM) de nouvelle génération ; jusqu’à 10 fois plus grands que GPT-4 ou Gemini. Cerebras argue que « l'apprentissage d'un modèle à un billion de paramètres sur le CS-3 est aussi simple que l'apprentissage d'un modèle à un milliard de paramètres sur les GPU ».
En pratique, le CS-3 peut être configuré en clusters allant jusqu'à 2048 systèmes. Les configurations compactes à quatre systèmes permettent d’affiner des modèles 70B en une journée, tandis qu'à grande échelle, 2048 systèmes sont en mesure d’entraîner un modèle Llama 70B à partir de zéro dans le même laps de temps.
Concernant l’aspect logiciel, la dernière version de Cerebras Software Framework offre un support natif pour PyTorch 2.0. Elle supporte également la dispersion structurelle dynamique et non structurée qui peut accélérer l'entraînement - jusqu'à huit fois plus vite que les méthodes traditionnelles aux dires de l’entreprise.
Par rapport aux GPU, Cerebras met en avant deux autres facteurs. Le premier a trait à la consommation. La société souligne qu’alors que la consommation d'énergie des GPU double d'une génération à l'autre, le CS-3 double les performances tout en restant dans la même enveloppe énergétique. Parler d’une consommation doublée est exagéré, mais effectivement, les accélérateurs AMD et cGPU NVIDIA sont de plus en plus gourmands au fil des générations. Le prochain GPU Blackwell engloutirait jusqu’à 1000 W, soit 300 W de plus que Hopper. Cerebras ne communique aucune valeur pour le WSE-3, mais pour le WSE-2, il était question de 15 kW par processeur ; nous resterions donc dans ces eaux-là.
Le second concerne la facilité d’utilisation. L'entreprise prétend que l'apprentissage des grands modèles de langage sur ses systèmes nécessite jusqu'à 97 % de code en moins par rapport aux GPU. Elle donne l'exemple d'un modèle de taille GPT-3 n'ayant requis que 565 lignes de code sur sa plateforme Cerebras - un record, selon elle.
Andrew Feldman, PDG et cofondateur de Cerebras, a déclaré :
« Lorsque nous nous sommes lancés dans cette aventure il y a huit ans, tout le monde disait que les processeurs à l'échelle du wafer étaient une chimère. Nous ne pourrions être plus fiers de présenter la troisième génération de notre puce d'IA révolutionnaire à l'échelle du wafer. WSE-3 est la puce d'IA la plus rapide au monde, conçue pour les derniers travaux d'IA de pointe [...] Nous sommes ravis de commercialiser WSE-3 et CS-3 pour aider à résoudre les plus grands défis de l'IA d'aujourd'hui. »
Cerebras fait état d’un carnet de commandes déjà bien rempli pour le CS-3. Le communiqué contient des déclarations intéressées des responsables du Laboratoire national d'Argonne et de la Mayo Clinic, notamment.
Déjà, la société d'intelligence artificielle G42 et Cerbras ont annoncé la construction de Condor Galaxy 3. Un supercalculateur doté de 64 systèmes CS-3 « qui fournira 8 exaFLOPs d'IA avec 58 millions de cœurs optimisés par l'IA ». Situé à Dallas, au Texas, ce Condor Galaxy 3 portera le total actuel du réseau Condor Galaxy à 16 exaFLOPs (puisque vous l'aurez compris, il existe déjà des supercalculateurs Condor Galaxy 1 et Condor Galaxy 2).

Condor Galaxy 3 © G42
Kiril Evtimov, directeur technique du groupe de G42, s’est félicité :
« Avec Condor Galaxy 3, nous continuons à réaliser notre vision commune de transformer l'inventaire mondial de l'intelligence artificielle grâce au développement des superordinateurs d'IA les plus grands et les plus rapides au monde. Le réseau Condor Galaxy existant a formé certains des meilleurs modèles open-source de l'industrie, avec des dizaines de milliers de téléchargements. En doublant la capacité à 16 exaFLOPs, nous sommes impatients de voir la prochaine vague d'innovation que les supercalculateurs Condor Galaxy peuvent permettre. »
Vous pouvez consulter les communiqués de presse de Cerebras et G42 ici.





















