Découvrez cette méthode secrète d'IBM pour augmenter la taille de son cache, les médecins en sont jaloux ! |
————— 10 Mars 2020 à 19h18 —— 25048 vues



Découvrez cette méthode secrète d'IBM pour augmenter la taille de son cache, les médecins en sont jaloux ! |
————— 10 Mars 2020 à 19h18 —— 25048 vues
Autrefois grande reine de l’informatique, IBM a peu à peu perdu de sa superbe — citons notamment la vente de la partie ThinkPad dont la qualité était éprouvée à Lenovo — au point d’être désormais cantonné aux serveurs, autant sur le plan matériel que logiciel, et aux projets concernant le quantique.
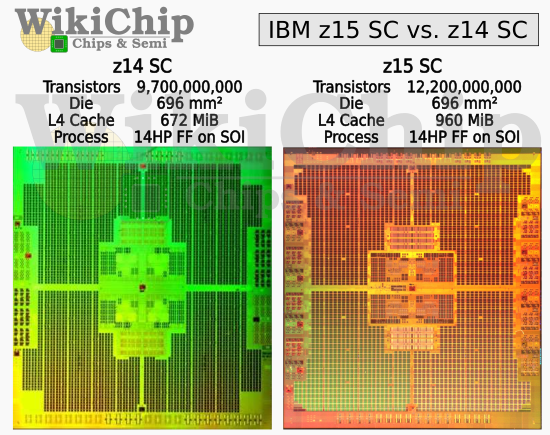
Parmi les CPU de la firme, la série des POWER reste familière aux oreilles du grand public (en grande partie par son intégration via les PowerPC dans les machines d’Apple jusque 2003), mais les zEntreprises sont bien moins renommées. Le dernier en date, nommé z15, suit (logiquement) le z14, en conservant certaines de ses caractéristiques : gravure 14 nm de chez GloFlo (la version co-designée mêlant FinFET et SOI, cela dit), fréquence de 5,2 GHz, dies de 696 mm². Néanmoins, le nombre de cœurs est passé de 10 à 12, le cache L4 de 672 Mio à 960 Mio et les caches L2-I et L3 ont tout simplement doublé de volume. Ces améliorations permettent au 14 nm de se vanter d’être la technologie actuelle la plus dense en matière d’intégration de la mémoire, meilleure encore que la SRAM 5 nm encore en développement chez TSMC.
Par quelle magie ? Tout d’abord, le processus de gravure hybride réutilise un des savoir-faire « magiques » de la firme : le DTC (Deep Trench Cell, n’est-ce pas..), permettant d’intégrer des condensateurs de manière très dense au sein du silicium et ainsi réaliser les caches à partir d’eDRAM. Pour donner quelque chiffres, une cellule s’intègre avec cette technologie sur 0,017 4 µm², contre 0,021 µm² pour le 5 nm précédemment cité.
Mais ce n’est pas cette technologie qui a permis l’augmentation de la densité, puisque le z14 était également gravé via le procédé 14HP. En fait, il s’est avéré que les marges prises lors de la gravure du L3 et L4 étaient suffisamment importantes pour pouvoir doubler les tailles des bitlines et wordline sans augmentation significative de la surface. De plus, des optimisations ont été effectuées au sein de l’alimentation, autant au niveau des tensions que de certains circuits passant en dehors du die, totalisant ainsi 80 % de stockage supplémentaire par unité de surface (de mémoire seule) par rapport à la version précédente. Décoiffant !
De tels progrès architecturaux sont impressionnants, et non sans écho auprès d’Intel, qui est également resté sur la même finesse — commercialement, tout du moins — pour la gamme des CPU de bureaux et serveurs. Certes, l’architecture Skylake n’est pas du tout celle d’IBM, mais il ne fait aucun doute que certaines optimisations auraient pu voir le jour — ce qui a déjà été le cas, finalement, avec la multiplication du nombre de cœurs. Rappelons toutefois que des gains aussi conséquents sont rares et nécessitent un investissement conséquent dans le développement des puces (choix qui n’a manifestement pas été pris par Intel, préférant à cela le nœud 10 nm, pour continuer le parallèle). De quoi prolonger encore un peu plus la vie du 14 nm ? (Source : WikiChip)
| Un poil avant ?Intel ferait du pied à TSMC pour ses GPU Xe ? | Un peu plus tard ...Les prix de toute la 10e génération Comet Lake révélés ? Et alors, cette concurrence ? | |





















