La seconde génération d’accélérateurs MTIA de Meta pour l’IA a subi une cure anabolisante |
————— 11 Avril 2024 à 12h38 —— 27042 vues



La seconde génération d’accélérateurs MTIA de Meta pour l’IA a subi une cure anabolisante |
————— 11 Avril 2024 à 12h38 —— 27042 vues
Les domaines d’activité du groupe Meta, anciennement Facebook – et à ce titre pierre angulaire de l’acronyme GAFAM (Google, Apple, Facebooke et Amazon et Microsoft) – ne se limitent pas à des réseaux sociaux pour boomers esseulés ou autres excités de la photographies ; ils englobent aussi la conception de puces. L’entreprise vient de présenter sa deuxième génération de MTIA (Meta Training and Inference Accelerator) conçus pour des modèles d’IA à grande échelle.

MTIA Gen 1 (à droite), MTIA Gen 2 (à gauche) © Arte
Cette nouvelle cuvée pour se résumer de la sortie « plus gros, plus puissant, plus performant ». Pour faire une analogie Peter Jacksonienne – ou Tolkenienne, au risque de s’exposer à un laïus sur l’inexactitude du propos, suivie d’une généalogie complète de toutes les races d’orques et d’une réflexion ethnographique sur ce qui différencie, ou non, un orque d’un Uruk-hai et d’un gobelin, lesquels seraient de toute façon bien inoffensifs car carencés en vitamine D, selon les conclusions de l’étude d'hobbitologie réalisée par les scientifiques de Tu mourras moins bête, et toc ! – cette seconde génération serait un peu l’équivalent des Uruk-hai de Saroumane, alors que la première génération s’apparenterait davantage aux chétifs orques de l’armée de Sauron (voire aux couards gobelins de la Moria).
La nouvelle puce de Meta a une surface de 421 mm² contre 373 mm² pour l’ancienne ; le TDP bondit de 25 W à 90 W, et la fréquence de 800 MHz à 1,35 GHz. La production est toujours confiée à TSMC, mais en 5 nm plutôt qu’en 7 nm.
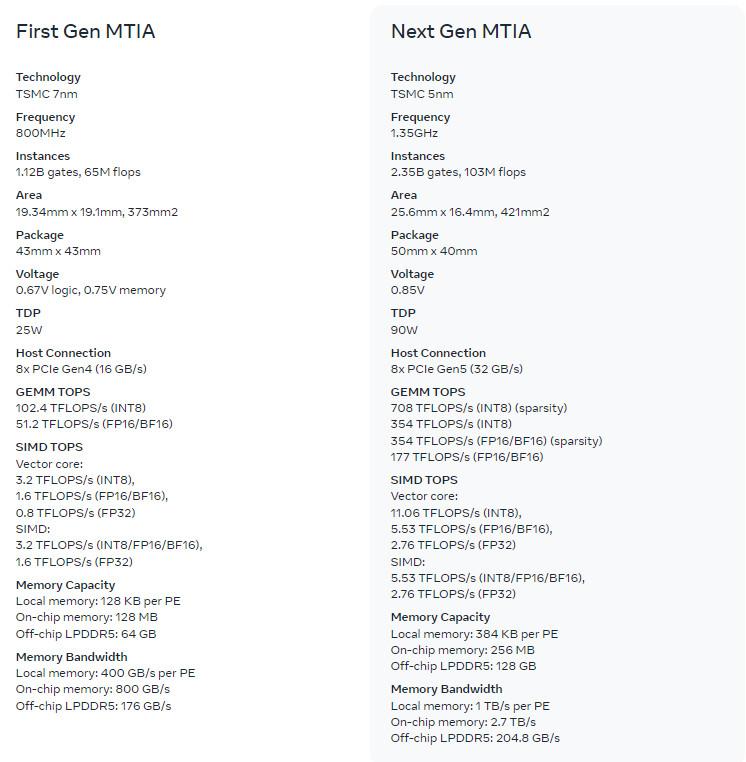
Comparaison MTIA Gen1 / Gen2 © Meta
Pour son silicium de nouvelle génération, Meta a élaboré un rack qui peut contenir jusqu'à 72 accélérateurs. Il se compose de trois châssis, chacun contenant 12 cartes qui hébergent chacune deux accélérateurs (donc 2 x 12 x 3, ce qui donne bien 72). Chaque paire possède 128 Go de mémoire LPDDR5 et se connecte aux onze autres en PCIe Gen 5 x8.

Frodon, seul après sa brouille avec Sam au sujet de leur enfant adoptif Gollum © Meta

Frodon et Sam réconciliés <3 © Meta
Chaque accélérateur peut traiter 708 TeraFLOPS en INT8 avec dispersion structurelle (354 TeraFLOPS sans), 354 TeraFLOPS en FP16/BF16 avec dispersion structurelle, 177 TeraFLOPS sans. C’est donc une hausse considérable par rapport à la première gen, puisque celle-ci plafonne à respectivement 102,4 TFLOPS et 51,2 TFLOPS. Meta revendique une augmentation d'un facteur 3,5 par rapport à MTIA v1 sans dispersion structurelle, d'un facteur 7 avec.

Plusieurs cartes MTIA © META
L’entreprise justifie les gains en ces termes : « Cela est dû en partie aux améliorations de l'architecture associées à la mise en pipeline des calculs avec dispersion structurelle. Elle provient également de la manière dont nous alimentons la grille PE [processing elements] : nous avons triplé la taille du stockage PE local, doublé la mémoire SRAM sur puce et augmenté sa bande passante de 3,5 fois, doublé la capacité de la mémoire LPDDR5 ».
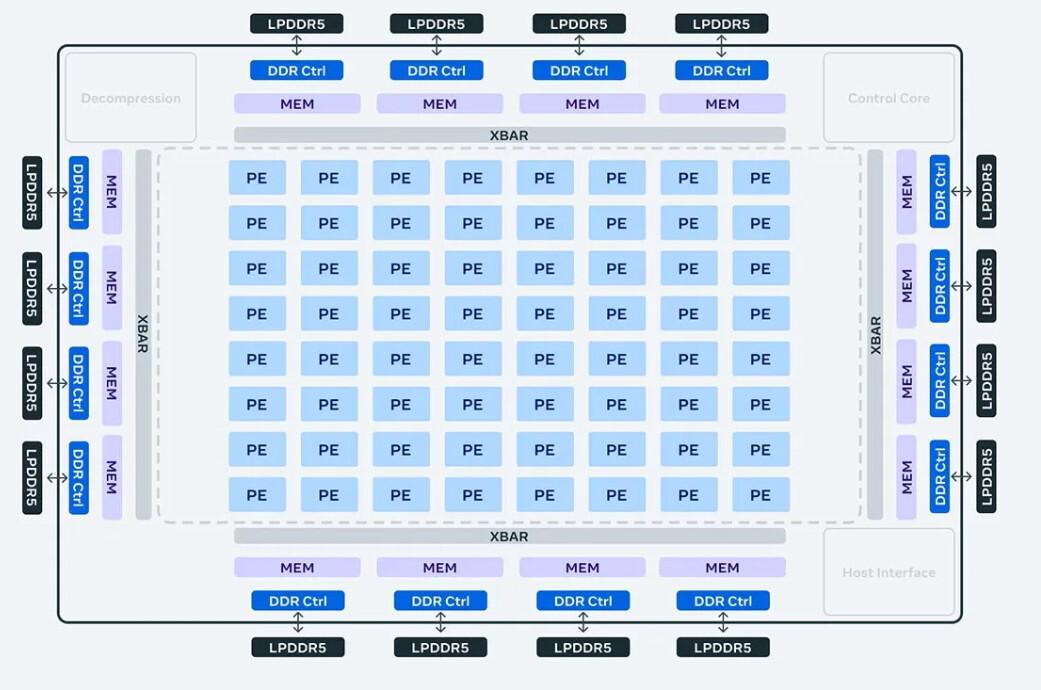
Schéma structurel © Meta
L'accélérateur MTIA est spécialement conçu pour l'entraînement et l'inférence de l'IA sur le framework d'IA PyTorch de Meta, avec un backend Triton open-source qui produit un code de compilateur. Meta l'utilise pour tous ses modèles Llama, dont la version Llama3 doit d’ailleurs être disponible dès la semaine prochaine.
| Un poil avant ?Le tremblement de terre à Taïwan ne va pas faire exploser le prix de la DRAM | Un peu plus tard ...Des APU sans iGPU ou des CPU ? On marche sur la tête chez AMD ! | |





















