Preview • Les puces Lunar Lake en détail, et sans HyperThreading |
• 04 Juin 2024



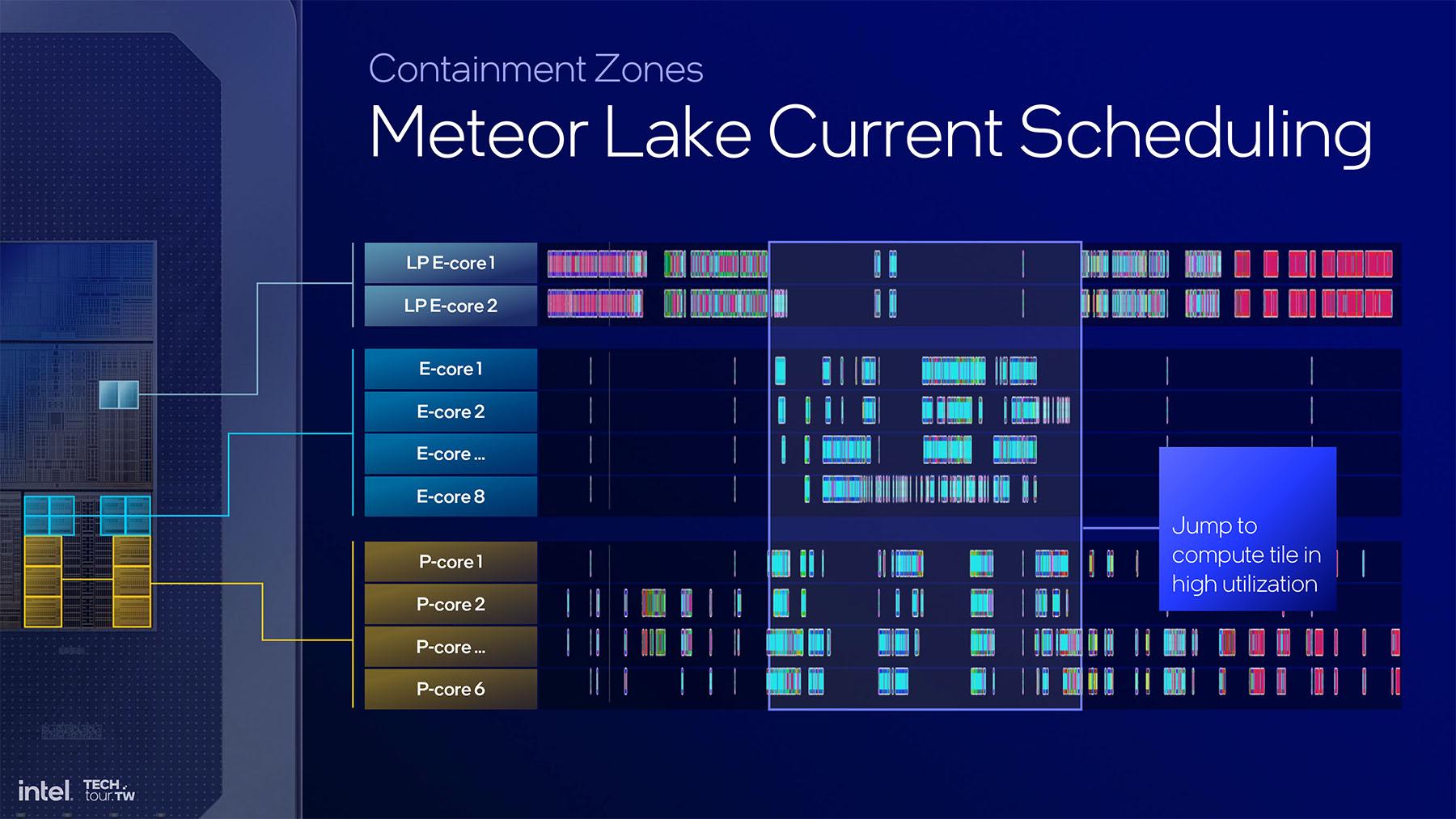
Pour les E-cores, Intel a tout changé. Plutôt que de se reposer sur 2 LP E-cores et un second cluster de 4 ou 8 E-cores, cette fois il n’y a plus qu’un cluster de 4 E-cores. Naturellement, les E-cores étant globalement plus intéressants sur le plan énergétique que les P-cores, Intel a simplifié son design en fortifiant ses E-cores et ainsi limité le nombre de fois où il est nécessaire de réveiller les P-cores, puisque cette étape consomme de l'énergie, tout en s'affranchissant de 2 clusters d'E-Cores. Voila qui facilite et la tâche du Thread Monitor. Celui-ci tente désormais de garder un maximum de tâches sur les E-cores, ce qui permet de ne réveiller les P-cores que lorsque c'est nécessaire.
![Avec Meteor Lake, pas facile de savoir sur quel core exécuter une tâche. [cliquer pour agrandir]](/images/stories/_cpu/5nm-20a_intel/lunar-lake/intel-lunar-lake-scheduling-mtl_t.jpg "Si vous cliquez, vous cliquez.")
![Avec Lunar Lake, l'OS essayera de se contenter au maximum des E-cores. [cliquer pour agrandir]](/images/stories/_cpu/5nm-20a_intel/lunar-lake/intel-lunar-lake-scheduling_t.jpg "La magie de la loupe, sans loupe")
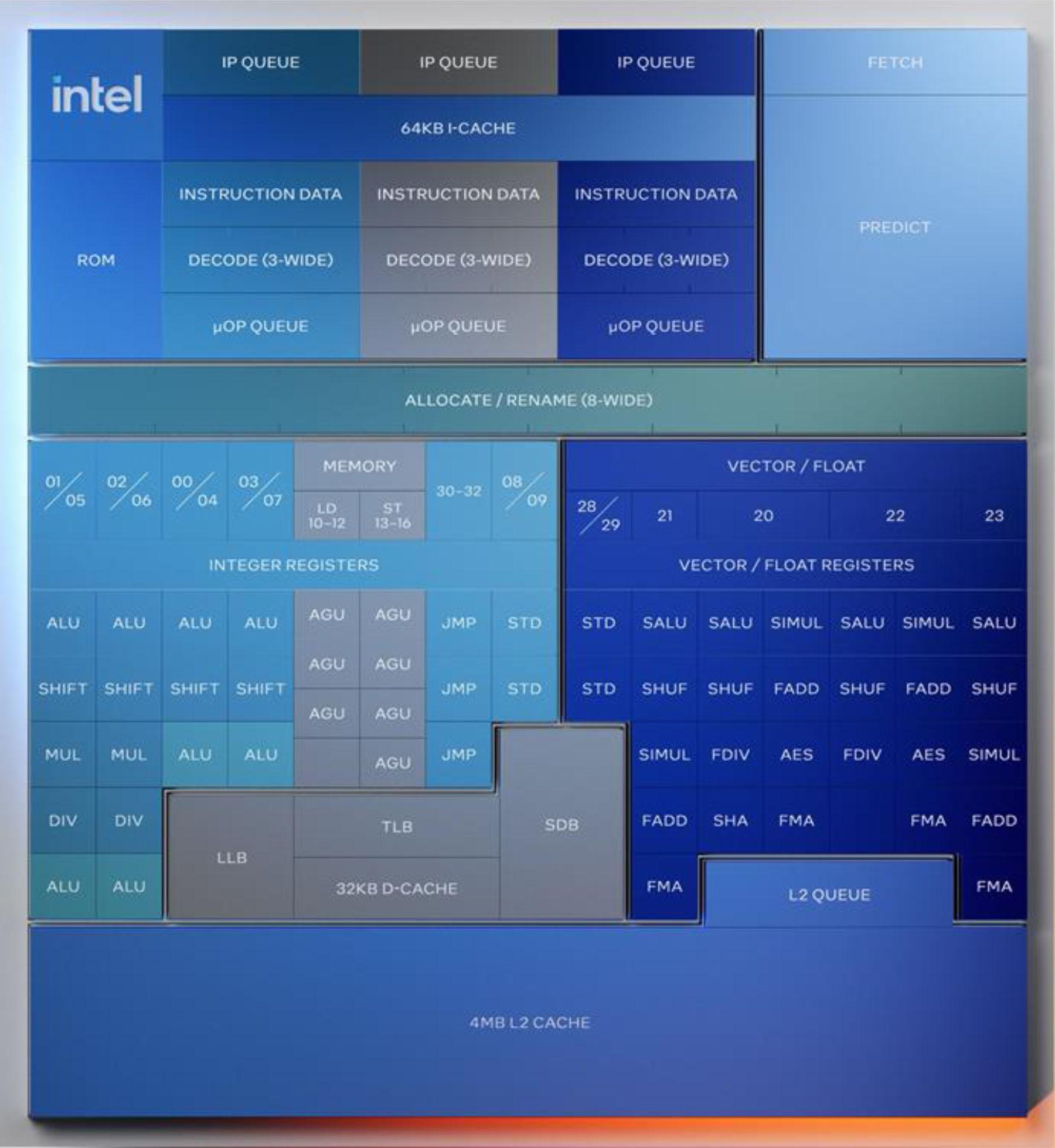
Tout comme les P-Core, les E-core Skymont se voient remaniés coté front-end et back-end en profondeur, et comme ils ont atteint l'âge adulte, ils deviennent indépendants — physiquement parlant. Aussi la prédiction de branchement se voit portée à 128 octets pour un maximum de 96 instructions, quand les décodeurs passent de 2 à 3 (on vous laisse faire le calcul en pourcentage) pour balancer tout cela au back-end. La file d'attente des µOps contient désormais 96 entrées contre 64 précédemment. Intel à également implémenté le nanocode, autorisant des accès simultanés au microcode par chacun des décodeurs.
On retrouve sur le back-end 26 ports d'exécution : 8 destinés aux unités des entiers, 4 ports destinés aux unités des flottants, 4 destinées au stockage, 3 destinés aux branchements et 3 destinés aux chargements/cycle.
![Le core Skymont de Lunar Lake. [cliquer pour agrandir]](/images/stories/_cpu/5nm-20a_intel/lunar-lake/intel-lunar-lake-skymont_t.jpg "Enlarge your pe...icture")
Une fois encore, Intel a balancé du cache à gogo afin de régler les problèmes, et ça se traduit par un cluster de 4 cores qui bénéficie de ses 4 Mo de L2, alors que les anciens E-cores devaient taper dans le L2 des P-cores. La bande passante a également été doublée (par rapport au cache des LP E-cores). Plus de L3 en revanche, et ces pauvres E-cores devront se contenter du side-cache, si celui-ci est disponible.
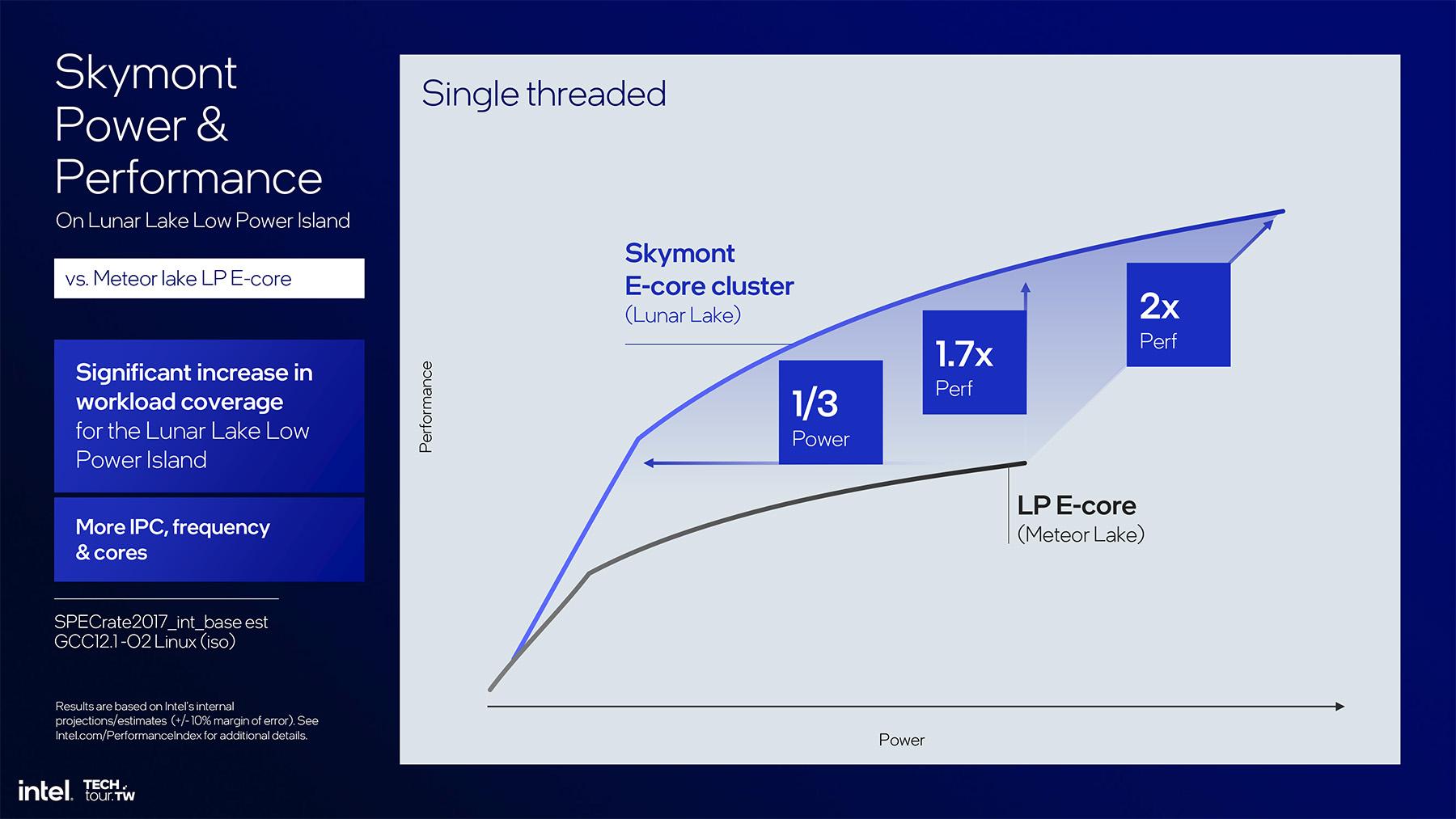
![Les E-cores Lunar Lake sont 70% plus rapides que les LP E-cores Meteor Lake, ce qui leur permet de traiter plus de tâches [cliquer pour agrandir]](/images/stories/_cpu/5nm-20a_intel/lunar-lake/intel-lunar-lake-skymont-vs-crestmont-efficiency-single_t.jpg "Ultra bouzotron HD max def")
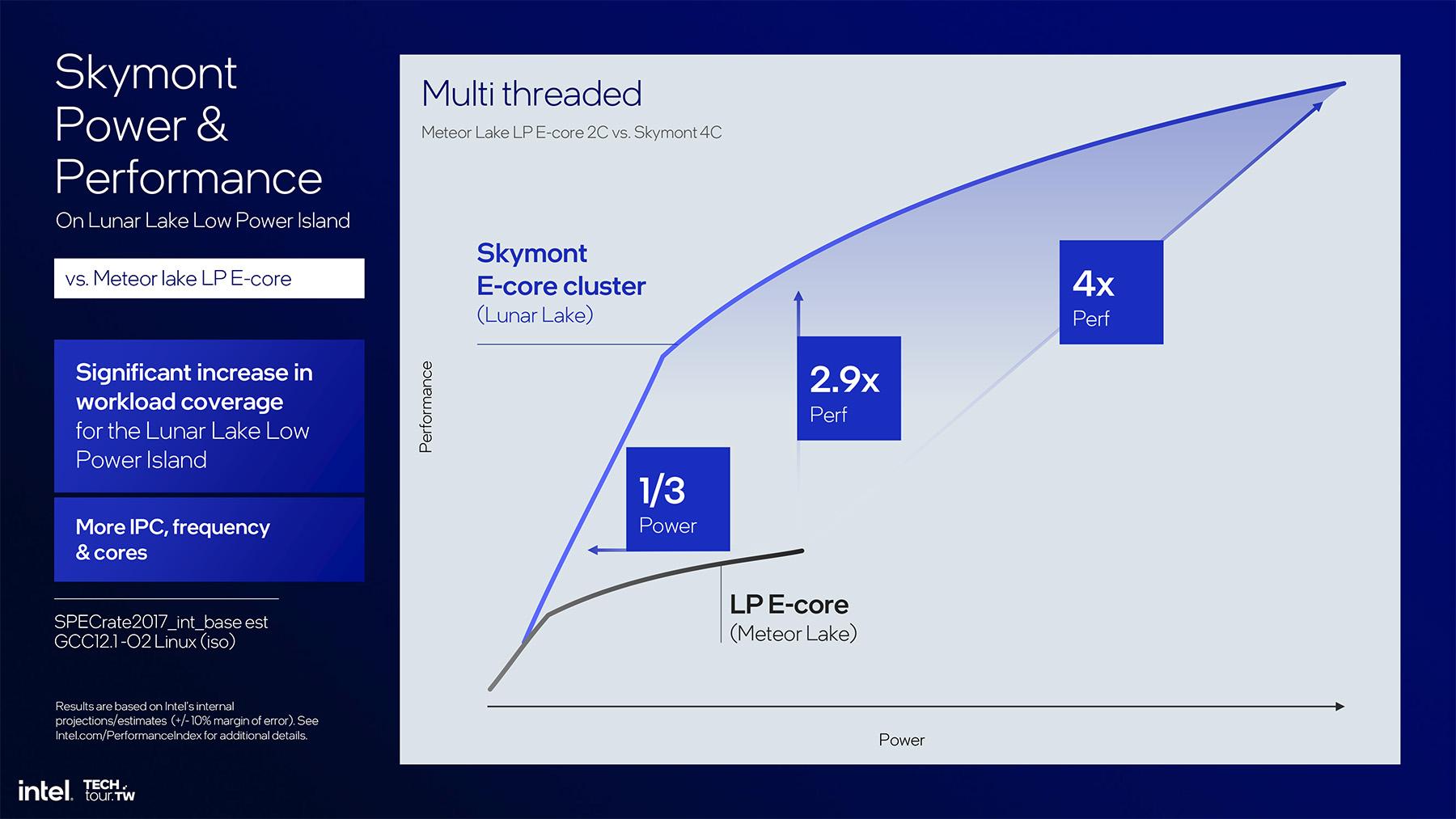
![Sans surprise, avec 4 cores au lieu de 2, la partie basse puissance de Lunar Lake écrase celle de Meteor Lake en multi-threading. [cliquer pour agrandir]](/images/stories/_cpu/5nm-20a_intel/lunar-lake/intel-lunar-lake-skymont-vs-crestmont--efficiency-multi_t.jpg "La magie de la loupe, sans loupe")
Cependant, malgré une pléthore de chiffres il est compliqué de dresser une comparaison directe afin de situer les cores Skymont par rapport aux anciens E-cores Crestmont de Meteor Lake. Intel les compare en effet uniquement aux anciens LP E-cores. Et après tout, pourquoi pas, Lunar Lake est destiné au marché ultra-mobile et donc l'accent est plus mis sur l'efficacité énergétique que la puissance. Mais le fondeur semble confiant sur le fait d’avoir trouvé un bon équilibre entre gain de performance et amélioration de l’efficacité énergétique. Vous pouvez toutefois retenir ce chiffre : les E-cores Skymont sont 70% plus rapides à consommation comparable que les LP E-Cores Meteor Lake !
Ce qui est certain, c’est que tout ceci simplifie grandement le die et donc potentiellement les couts. En parallèle, Intel a aussi travaillé sur son Thread Director, qui permet d’assigner les tâches aux cores les plus adaptés, mais en débutant toujours par un E-core, puis en passant à plusieurs, ou aux P-cores en fonction des besoins. Une approche qui privilégie l’autonomie au détriment de la rapidité, mais Intel aura pris soin d’intégrer des bypass pour certaines tâches qui seront directement affectées à la configuration la plus adaptée d’après les algorithmes de la marque.
|
|
| Un poil avant ?Asus met au monde sa troisième génération d’alimentations ROG Thor | Un peu plus tard ...Acemagic dévoile un PC portable double écran et des mini-PC bling-bling | |
| 1 • Préambule |
| 2 • Des P-cores qui picotent |
| 3 • |
| 4 • IA et partie graphique |
| 5 • Connectique |